
Speech Recognition
Written by Marco Sartori , Mercury Communications
![]() 2007
network writings:
2007
network writings:
![]() My
TechnologyInside blog
My
TechnologyInside blog
� Mercury Communications Ltd - April 1995
In any science fiction story computers that understand spoken orders are regarded as commodity items, along with warp drives and teleporters. As yet there has been little progress towards the latter two but the former is fast approaching the status of an accepted technology.
The market for such products is growing steadily; market intelligence reports indicate that voice recognition systems market grew from a value of $381 million in 1988 to projected levels of $1.4 billion in 1994 and $2.5 billion by 1998. A market analysis shows the relative importance of various sectors, see figure 1.
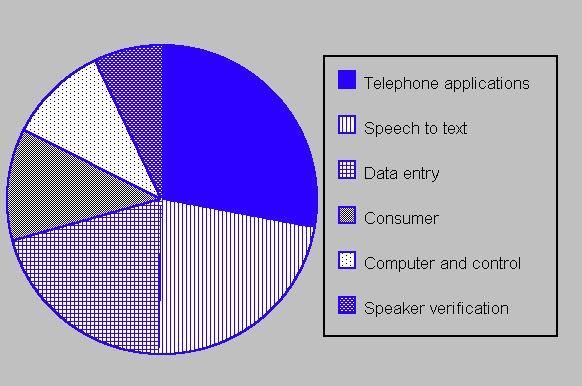
Figure 1 (Source: Voice Information Associates)
Speech recognition comes in many different guises and fulfils the need of many diverse applications leading to differing implementations of this technology. It is possible, however to group the technologies associated with speech recogition systems into broad areas and these are depicted in figure 1.
Throughout this text I shall use the term speech recognition to mean the ability of a system to use speech as an input signal, but many texts use the term voice recognition instead, a term that is arguably semantically incorrect.
Figure 2
Speaker verification
The aim of this group of applications is to use voice as a secure methods of identifying individuals by pattern matching a sample of voice with a pre-recorded sample. Such a system needs only to recognise a few words but the matching algorithm must be very reliable to ensure security.
A system called SpeakerKey from ITT is currently being trialed to verify that prisoners sentenced to home incarceration are actually at home. To accomplish this a computer telephones the offenders house and requests them to speak a randomly selected series of digits which is matched with the existing �voiceprint�.
Speaker identification also has applications in banking, perhaps with the voice parameters stored on a smartcard, calling card user verification, and secure access to computer systems or even buildings.
Natural language processing
Consider the simple spoken command, �Computer, turn on the lights and boil the kettle�. The computer could understand this command in syntax only and the result would be an attempt to sexually arouse the lights and place the kettle in boiling water. Such a sentence can only be correctly interpreted by reference to a store of background knowledge which is usually only applicable when the recognition system operates in certain specific, predefined domains.
One early application of this technology translates a natural language request from a person wishing to search a database into a regimental, formatted request covering all possibilities that can be understood by a computer.
A very important and advanced market for natural language processing is that of an Air Traffic Information Service (ATIS). Such systems consist of a speech recognition front end followed by a natural language understanding module and are capable of answering complex inquiries such as �Show me all flights between Denver and Dallas tomorrow that serve breakfast�, followed by �Only show me First Class�. A demonstration of a trial system from the Stanford Research Institute showed that it was difficult to ask the questions in a manner that the system could not �understand�. This technology is being developed commercially by a subsidiary called Corona Corporation.
It is natural language processing that could provide real competitive advantage for the new IN platforms by differentiating similar functional offerings with an intuitive user interface. The IN platform could provide the functionality to implement the spoken command, "I�ll be on the mobile for the next two hours and after that transfer all calls to voice mail."
Independent speaker speech recognition
In this realm it is common to use a technique called keyword spotting to identify a limited number of words from an input stream containing a larger vocabulary. Many systems in this domain have limited vocabulary, for example the numbers 0 to 10 and �yes� and �no", thus enabling the system to recognise previously unencountered speakers.
It also enables recognition to be achieved over telephone lines since the limited bandwidth, differing telephone microphones and the channel noise associated with the PSTN, all collaborate to degrade the speech signal. Communications over a mobile channel present even worse problems; it is difficult enough for the processing power of the human brain to understand what is being said by someone on a mobile phone.
Newer telephone based systems however have advanced considerably, for example Stock Talk from Northern Telecom (see later) has a vocabulary of some 3000 words or phrases active at any one time. This trial system uses a vocabulary swapping approach based on the response from a question; in this case, "which financial exchange do you require?", in order to make reference to the correct vocabulary. Not only does this improve accuracy but also lightens the processor load for systems aiming to deal with many simultaneous calls.
Other than applications over the PSTN, keyword spotting techniques have been suggested for use in starting a recording apparatus only when certain words are detected in a stream of speech. This could find applications for the clandestine bugging done by intelligence agencies, and for monitoring air traffic control transmissions to build up an accident log.
Further applications involve the use of speech as a control mechanism for discrete processes such as ordering fast food. A consumer application announced recently is a set top box with speech recognition software from BBN Hark Systems Corp. enabling channels to be changed on a cable TV system.
Speaker dependent voice recognition
In order to produce a true dictation style voice to text system commercially available products require that the system is personalised for the users voice.
Such systems rely on producing a model of the users voice which stores detailed parameters, thus enabling more reliable recognition to be achieved. Until recently the input to commercially available voice to text systems has required a pause to be inserted between each word which. means. the. user. still. has. to. alter. his. or. her. method of speaking to interface with the system. This is to allow the speech recogniser to clearly distinguish where one word ends and another begins.
However, a recent announcement made by Philips Dictation Systems claims the worlds first continuous speech, large vocabulary recognition system. The philosophy behind this product is to use the desktop PC as a digital tape recorder to create a data file which is then processed as a background task by a server. This enables the user to edit the document at a later stage whilst retaining a recording of the speech to use for reference when words are interpreted incorrectly.
Moving away from what is commercially available the picture suddenly becomes quite different and perhaps gives an encouraging view of the future. Given the power of a high end workstation true speech to text systems are unshackled from the need for speaker dependence and operate successfully in the realm of speaker independence.
How do speech recognition systems work?
It is difficult to give a definitive account of how speech recognition systems operate since the requirements for each application are so specific that this leads to a tailor made solutions.
A good example however, is the operation of a large vocabulary speech to text system and this is described below.
1) The analogue speech is digitised by a A to D converter.
This step can be performed by a generic sound card or by a software specific card which also contains a Digital Signal Processor (DSP) chip. The advantage of using a dedicated DSP chip is it performs computationally intensive manipulation of the data. This includes performing a Fast Fourier Transform on a centisecond 'slice' of the input waveform to convert a signal into its constituent frequency components that then form the basis of the recognition process.
The DSP can also perform functions such as adaptive filtering on the input signal in an attempt to remove steady state background noises such as the hum from a computer fan.
Since all this processing is performed in the DSP the computational load on the processor is lightened, therefore enabling it to work more effectively on the higher levels of processing. This advantage, however, is quickly being eroded by the pace at which newer processors are increasing in MIPS capability. At the Computer and Telephony '95 conference in Dallas, Intel were promoting the idea of �Natural Signal Processing�, where software will use the Pentium or P6 processing power to perform signal analysis. This has the user advantage that the installation of a piece of new hardware is not required nor all the reconfiguration that goes with it.
2) Acoustic Matching
The aim of this stage is to match the characteristics of the input sound to a library of possible sounds. Each sound slice is examined in an attempt to match this with a particular subphoneme. A subphoneme constitutes the 'building blocks' of speech and many such subphonemes are needed to represent a typical English letter.
A technique called a Hidden Markov Model has gained favour during the 1980�s and continues to dominate in the 1990�s as a method of decided when a match has occurred.
A Hidden Markov Model is a statistical model that is used when the output from a process is a probability distribution and only the output can be observed, not the process that is producing the output. A HMM applies to language because an initial sound will directly influence the sounds that follows. An analogy with written English is the way that a �u� will normally follow a �q�. An HMM of a particular subphonetic sound will recognise only that sound and a series of subphonetic matches will enable the stored dictionary to be consulted and the word recognised.
The HMM�s used in speech recognition are initially trained to respond to words using speech from numerous speakers, including speakers with different accents. Speaker dependent systems then continue to refine the model when the user enrols the system by reading sentences to the system. During use, the training continues in 'error mode' in which mistakes are corrected by the user and the system fine tunes the speech model.
3) Adaptive Language Model
This model is used to analyse words when considered as groups of two, three or even four words. The model is based on statistical word usage so that more commonly used words are selected above rarely used alternatives.
This model may also extend to incorporating grammatical rules which impart to the system a degree of natural language understanding. It is only in this way that phonoyms can be distinguished, for example, �Too many people� or �To many people� could not otherwise be distinguished.
This stage can be seen in operation with the IBM Personal Dictation System which goes back to correct phononyms once the sentence has ended and the 'meaning' has become clear.
4) Final output.
An arbiter between the adaptive language model and the acoustic matching process is used to determine the most likely words that were spoken by the user. The other alternatives can be offered to the user as a shortlist of alternatives if the chosen word is incorrect.
The ARPA tests
The ARPA(Advanced Research Projects Agency) tests for speech recognition constitute the world speech recognition Olympics. The tests, which are actually carried out by NIST (National Institue of Standards and Technology), consist of measuring the accuracy of independent speaker voice to text translation and also the accuracy of responses to natural language requests.
The competitors for this event come from companies which are already in the speech recognition market, such as Dragon systems and also universities. The conditions are somewhat artificial in these tests as the software runs on high end workstations using vast memory, e.g. 100 Mega Bytes and does not run in real time.
The winning system in 1995's tests was from Cambridge University and had an error rate of just 7.2% when tested with an unlimited vocabulary input and an active vocabulary of 20,000 words in the system. The fact that the input vocabulary is unlimited but the recogniser's vocabulary is limited means that there will always by an irreducible error rate. This is thought, however to simulate a real system and by removing this irreducible error rate the actual error rate drops to 5.2%. An interesting comparison is the error rate when the same test is performed with input speech recorded over telephone lines; the word error rate for the best system soared to 22.5%.
The natural language understanding test consists of a simulated Air Traffic Information System which forms an artificial driver in this very niche market. This test was won by a system from the Carnegie Mellon University which answered only 8.6% of spoken questions incorrectly.
Drivers for speech recognition.
Hardware
Firstly, improvements in hardware have contributed to the increasing feasibility of speech recognition. Due to the large quantity of data that is generated from a speech sampling process, coupled with the need to consult a huge stored dictionary of words in real time, substantial computing power is required. This power, until recently has only been available in yesteryears mainframes but has now migrated to the desktop and is arguably the greatest driver for the acceptance of speech recognition.
Coupled with the increasing speed of computers has been the increasing RAM and hard disk sizes that have enabled speech recognition applications to run on the desktop. The IBM system for example needs a minimum of 16 Mega Bytes of RAM and 62 Mega Bytes of hard disk space.
Further hardware developments include the availability of fast, relatively cheap Digital Signal Processors (DSPs). The importance of dedicated speech recognition DSP's will have a vital role to play in the mass consumer market to allow voice control to be incorporated cheaply into devices such as video remote controls.
Another hardware item receiving attention from designers of speech recognition systems is the microphone. Professional systems supply microphones with the system in order that it is matched to a particular sound card. Most manufacturers are moving away from this approach but a professional user will definitely want a headset mounted microphone and is unlikely to already posses one.
Control Interfaces
An important aspect of speech recognition is the ability to control the functions of an application with spoken commands. This requires a standard method of integrating speech recognition systems with existing applications.
Control interfaces have so far been limited to developers kits provided by the speech recognition vendors. However, companies such as Kurzweil, Novell-Word Perfect and IBM are now concentrating specifically on a cross platform speech recognition API whilst Microsoft has distributed a Resource Manager Interface ( a common interface to DSP's) and its speech recognition API for its 32bit Windows platforms.
Regulatory Drivers
The original speech recognition system from Kuzweil was tailored to the medical market and incorporated a front end to prompt the doctor to ask the correct series of questions to the patient. The success of this package was due to the substantially reduced liability insurance that GP's paid if this package was used.
A regulatory driver in the U.S. is the threat to legislate against dialling on a mobile phone whilst driving . A network based speech recognition platform would overcome this law by enabling hands free dialling.
Current applications
Current widespread use of speech recognition is confined two main areas, PC based speech to text dictation systems and telephony applications.
1) Dictation-type systems
Such systems are commonly used by specialised users, for example radiologists, e.g. Kurzweil and IBM, and the legal profession e.g. Kolvox and IBM. These groups are a market commonly attacked by speech recognition systems because these groups traditionally use dictation in their daily job and their sentence structure, although initially complex is actually quite predictable. Also the long words used by these professions are relatively easy for speech recognisers to identify, the word �cardiovascular� has a lengthy speech pattern (also termed �phonetically juicy' in the US) as opposed to �cat� and �mat' which contain only one syllable.
The final, and very important, advantage is that these long words will always be spelt correctly once they have been recognised.
PC systems in the real world
In tests recently carried out by computing magazines the IBM Personal Dictation System proved to be the most accurate. It is interesting to note, however that this test produced no editors choice since the IBM PDS was found to require the most training and did not allow any voice control of applications. For this reviewer, it seems, speech recognition has not arrived.
IBM claims a dictation speeds of between 70 and 100 words per minute are possible using their system and indeed users have proved the lower value is attainable. However, this relies on the user learning to insert the pauses between words and is also highly dependent on the content of the material being dictated.
2) Telephony applications
As more advanced services are offered by PTOs driven by Intelligent Network technology the user interface to such services becomes more difficult. An interesting statistic is that 70% of current European and Asian telephones do not use tone dialling. Speech recognition systems provide an intuitive way for any user interact with new services.
Current telephony applications
Examples of systems in current use include:
AT&T's Call routing system
This system uses mature technology to deal with operator assistance calls automatically. The caller is prompted to say the words "collect", "third party billing", "person to person", "calling card" and "operator". Although a message explains that the caller should only say one of the above options trials of this system indicated that one fifth of callers did not do as requested. Callers embedded these words in long sentences, such as "Um? Gee, okay, I'd like to place a calling-card call". Hence a keyword spotting algorithm was born that scans for particular words in the stream of speech.
The main success of the AT+T system is due to careful thought about the user interface including speaker independence, barge in and failure recognition with operator backup.
The system is projected to save AT&T $300million a year in operator costs and was recently claimed to handle in excess of 1 billion calls per year.
A similar system developed by BNR called Northern Telecom Collect Calling is claimed to be in with all the major RBOCs (Regional Bell Operating Company) in the U.S. and handles in excess of 1 million calls per day.
Wildfire Communications Electronic Assistant
Wildfire communications have a voice activated personal assistant service which aims to emulate a computerised secretary. The service performs a �follow me� function, allows users to access voicemail, call numbers in an electronic address book and dictate a reminder sound bite. The core offering of this system closely resembles the functionality of Mercury's OneCall but has been enhanced by the speech recognition front end. Wildfire have set up a demonstration number in the US on +1 617 6741590.
Stocktalk
A demonstration service from Northern Telecom that provides real time, up-to-the minute quotes for stock prices which is entirely voice driven. The user simply says the exchange on which the stock is quoted and the name of the stock. Although the system is optimised for North American English it is still remarkably robust. Demonstration phone number +1 514 765 7862. (Cable and Wireless is listed on the New York stock exchange.)
Thomas Cook's Flight booking system
Based on technology from a company called BBN Hark Systems this system allows travellers to book flights, car rental and hotels using speech responses. The booking is performed by answering a series of questions which makes reference to a database containing flight details and also information about the users preferred airlines and so forth.
Speech dialling
Companies such as SouthWestern Bell mobile services and Motorola are offering speech dialling and address book access to their customers. The main advantage of this system cited by these companies is the increased safety of voice dialling from a mobile phone whilst driving.
A niche market application of this technology from Brite Voice Systems Inc. allows a mobile user to automatically dial a number once it has been spoken by the synthesised voice of a directory enquiry system. This is in fact, in the author's view at least, the strangest way of exchanging digital information ever conceived!
The future
Speech recognition is still an emerging technology and the publicity surrounding it has so far been based on an insufficient user base to consider this technology mass market. Examples of early adopters include the British Computer Society which recently published an edition of its magazine Computer Bulletin with the text produced entirely by the use of speech recognition.
Certainly in niche application very specific systems will flourish. The telephone market will need to develop a large store of experience of user interaction and carefully design an interface with an acceptable user experience. Since the telephone network is a fixed system with fixed bandwidth, voice recognition will always have a difficult time in this domain but is being pushed hard by the new IN based services. This is certainly an area in which much research is taking place and companies such as BBN Hark systems and Northern Telecom have medium sized vocabulary systems that are speaker independent.
In the realm of particular market segments such as legal and radiology the current trials may lead to limited take-up of voice recognition. Also for handicapped people and those with injuries such as RSI (Repetitive Strain Injury), speech recognition provides an essential lifeline to enable people to continue their careers.
More development work is also needed to launch international versions of these products; not everybody in the world speaks North American English.
In summary speech recognition is developing steadily and will lumber slowly into everyday life principally driven by the increasing power in the desktop PC and also telephone applications using mature technology to develop simple voice driven services.